Kubernetes Service | ROAD TO CKA ☸️
Service Resource
쿠버네티스에서 파드(Pod)는 언제든 생성되고 사라질 수 있는 ‘휘발성(Ephemeral)’ 자원입니다. 파드가 재시작될 때마다 IP 주소가 변경되는 환경에서, 클라이언트나 다른 애플리케이션이 특정 파드를 안정적으로 찾는 것은 불가능에 가깝습니다.
Service(서비스) 리소스는 이러한 문제를 해결하기 위한 논리적인 추상화 계층입니다. 서비스는 다음과 같은 핵심적인 역할을 수행합니다.
- 안정적인 네트워크 엔드포인트 제공: 파드의 IP가 바뀌어도 변하지 않는 고정 진입점을 제공합니다.
- MSA의 느슨한 결합(Loose Coupling): 애플리케이션 간의 의존성을 IP 레벨이 아닌 논리적 이름(Service Discovery)으로 분리합니다.
- 트래픽 노출 및 부하 분산: 외부 사용자의 요청을 내부 파드로 안전하게 라우팅하고 로드밸런싱합니다.
그렇다면 Service는 구체적으로 어떤 방식을 통해 외부 요청을 처리하고, 내부 파드 간의 통신을 중개할까요?
쿠버네티스 서비스는 트래픽의 노출 범위와 목적에 따라 크게 다음 세 가지 유형(Type)으로 구분됩니다.
- ClusterIP
- NodePort
- LoadBalancer
각각의 특징과 통신 흐름을 시각 자료와 함께 자세히 살펴보겠습니다.
NodePort: 외부 접근을 위한 가장 기본적인 방법
개발 단계나 온프레미스 환경에서 파드(Pod)에 접근하기 위해 노드에 SSH로 접속하여 curl을 날리는 방식은 비효율적이며 확장성이 없습니다. 쿠버네티스는 이를 위해 NodePort라는 서비스 타입을 제공합니다.
NodePort는 이름 그대로 모든 노드(Node)의 특정 포트를 개방하여 외부 트래픽을 서비스로 유입시키는 방식입니다.
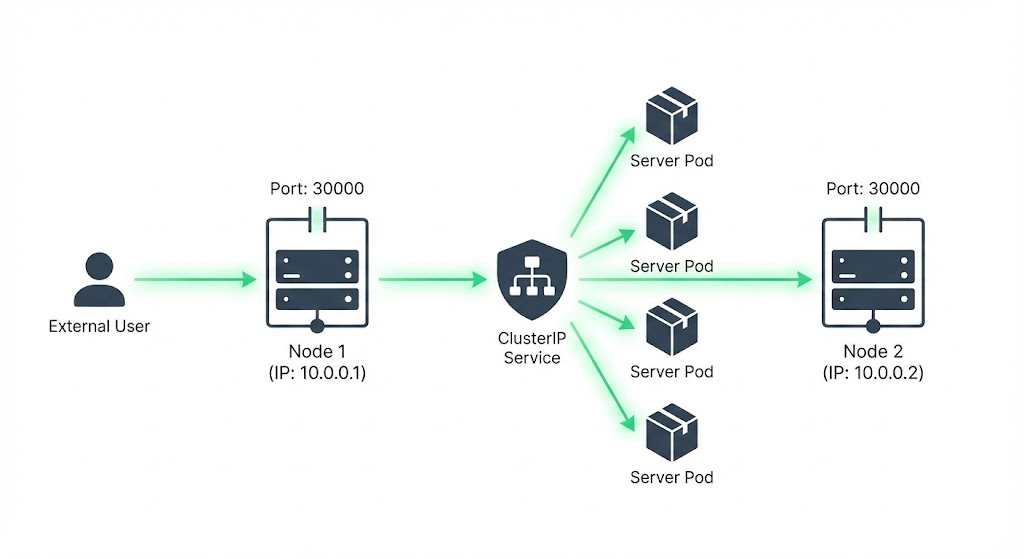
1) 포트 구성의 이해 (Port, TargetPort, NodePort)
NodePort 서비스를 정의할 때는 세 가지 포트의 개념을 명확히 구분해야 합니다.
- NodePort (30000~32767): 외부에서 노드에 접속할 때 사용하는 포트입니다. 별도로 지정하지 않으면 범위 내에서 랜덤하게 할당됩니다.
- Port: 서비스(Service) 리소스 자체가 내부적으로 노출하는 포트입니다. (ClusterIP 역할)
- TargetPort: 실제 파드(Container) 내에서 애플리케이션이 리스닝하고 있는 포트입니다.
Note: targetPort가 정의되지 않으면 기본적으로 port와 동일한 값으로 설정됩니다.
2) YAML 명세 및 생성
NodePort 서비스는 spec.type을 명시하여 생성합니다. ports 필드는 리스트 형태이므로 여러 포트를 매핑할 수 있다는 점에 유의해야 합니다.
yamlapiVersion: v1
kind: Service
metadata:
name: myapp-service
spec:
type: NodePort # 서비스 타입 지정
ports:
- targetPort: 80 # 파드(컨테이너)의 포트
port: 80 # 서비스의 포트
nodePort: 30080 # 외부 노출 포트 (미지정 시 자동 할당)
selector:
app: myapp
type: front-end
3) 동작 원리 및 트래픽 분산
Selector를 통한 파드 식별
서비스는 selector에 정의된 라벨(Label)과 일치하는 모든 파드를 찾아 자신의 엔드포인트(Endpoints)로 묶습니다. 파드의 개수가 아무리 늘어나거나 IP가 변경되어도, 서비스는 라벨을 기준으로 대상을 추적하므로 별도의 추가 구성이 필요 없습니다.
부하 분산 (Load Balancing)
동일한 라벨을 가진 파드가 여러 개일 경우, 서비스는 들어온 요청을 어떻게 처리할까요? 기본적으로 서비스는 랜덤 알고리즘(Random Distribution) 방식을 사용하여 연결된 파드들에게 트래픽을 적절히 분산시킵니다. 이를 통해 기본적인 로드밸런싱 효과를 얻을 수 있습니다.
멀티 노드 환경에서의 접근성
NodePort 서비스가 생성되면, 쿠버네티스는 클러스터 내의 모든 워커 노드에서 동일한 포트(예: 30080)를 개방(Listening)합니다. 즉, 서비스가 특정 노드에 종속되는 것이 아니라 클러스터 전체 레벨에서 선언되는 것입니다.
여기서 NodePort의 강력한 특징이 나타납니다.
- 파드가 특정 노드(Node A)에만 있는 경우: 사용자가 파드가 없는 Node B의 IP와 NodePort로 접속하더라도 연결은 성공합니다. 쿠버네티스의 네트워크 프록시(kube-proxy)가 내부 네트워크(NAT)를 통해 트래픽을 파드가 존재하는 Node A로 자동으로 라우팅해주기 때문입니다.
파드가 여러 노드(Node A, Node B, Node C)에 걸쳐 분산 배포된 경우에도 마찬가지입니다. 사용자는 어떤 노드의 IP를 선택하여 접속하든 상관없습니다. 클러스터로 들어온 요청은 selector로 묶인 모든 파드 중 하나로 적절히 분산(Load Balancing)되어 전달됩니다.
결론: 클라이언트는 파드가 실제로 어느 노드에서 실행 중인지 알 필요가 없습니다. 그저 “아무 노드의 IP”와 “지정된 NodePort”만 알면 서비스에 안정적으로 접근할 수 있습니다.
ClusterIP: 클러스터 내부 통신의 표준
쿠버네티스에서 ClusterIP는 가장 기본이 되는 서비스 타입(Default Type)입니다. 이름에서 알 수 있듯이 클러스터 내부(Cluster-Internal)에서만 유효한 고유 IP(Virtual IP)를 할당하여, 서비스 간의 안전한 통신을 보장합니다.
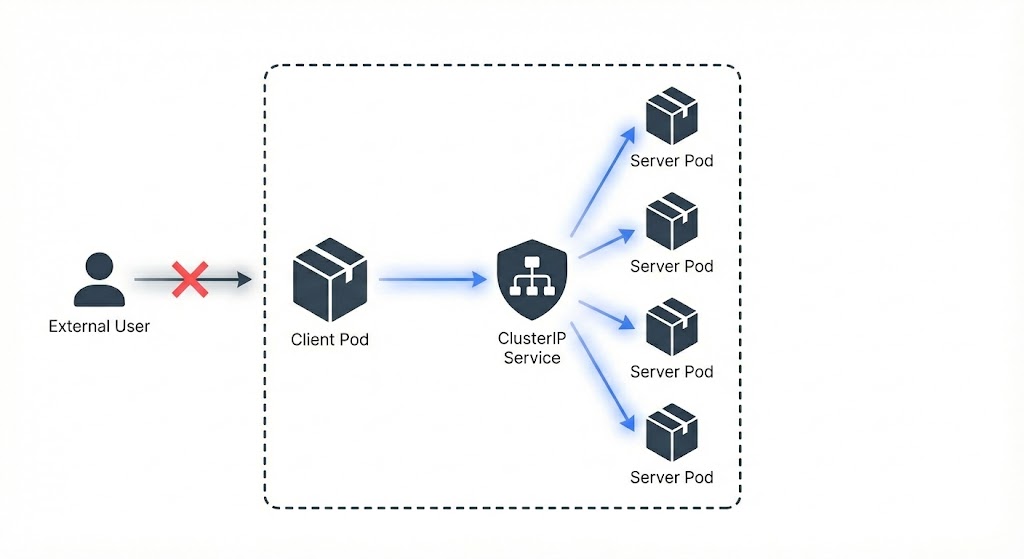
1) 왜 필요한가? : 파드 IP의 휘발성 문제
쿠버네티스 환경에서 파드(Pod)들은 각각 고유한 내부 IP를 할당받습니다. 하지만 이 IP는 영구적이지 않습니다.
- 업데이트나 장애 복구로 인해 파드가 재생성되면 IP가 변경됩니다.
- 백엔드 파드가 3개로 스케일 아웃(Scale-out)되면, 프론트엔드는 3개의 IP를 모두 알아야 할까요?
이처럼 수시로 변하는 파드의 IP를 직접 바라보고 통신하는 것은 불가능에 가깝습니다. 이를 해결하기 위해 ClusterIP가 등장합니다.
2) 단일 진입점(Interface) 제공 및 그룹화
Service(ClusterIP)는 selector를 통해 논리적으로 파드들을 그룹화하고, 이 그룹을 대표하는 단 하나의 고정 IP(VIP)를 생성합니다.
- 안정적인 인터페이스: 프론트엔드는 더 이상 백엔드 파드의 개별 IP를 알 필요가 없습니다. 변하지 않는 서비스의 ClusterIP(또는 도메인 이름)로만 요청을 보내면 됩니다.
- 내부 로드밸런싱: 서비스로 들어온 요청은 그룹화된 하위 파드 중 하나로 무작위(Random) 또는 라운드 로빈 방식으로 분산 전달됩니다.
3) MSA(Microservices Architecture)를 위한 느슨한 결합
이러한 구조는 MSA 기반 애플리케이션 구축에 핵심적인 역할을 합니다.
- 프론트엔드 ↔ 백엔드 ↔ DB 각 계층이 서로의 구체적인 위치(Pod IP)를 몰라도, 서비스 이름만으로 통신이 가능해집니다. 이를 통해 서비스 간의 결합도를 낮추고(Decoupling), 배포와 확장을 쉽고 효과적으로 만듭니다.
4) YAML 명세 및 생성
ClusterIP는 서비스 리소스의 기본값(Default)이므로 type 필드를 생략해도 생성되지만, 명시적으로 적어주는 것이 가독성에 좋습니다.
yamlapiVersion: v1
kind: Service
metadata:
name: back-end
spec:
type: ClusterIP # 생략 가능 (기본값)
ports:
- targetPort: 80 # 실제 파드(컨테이너)가 열고 있는 포트
port: 80 # 서비스(ClusterIP)가 노출할 포트
selector:
app: myapp
type: back-end # 이 라벨을 가진 파드들만 그룹화
LoadBalancer: 프로덕션 환경을 위한 단일 진입점
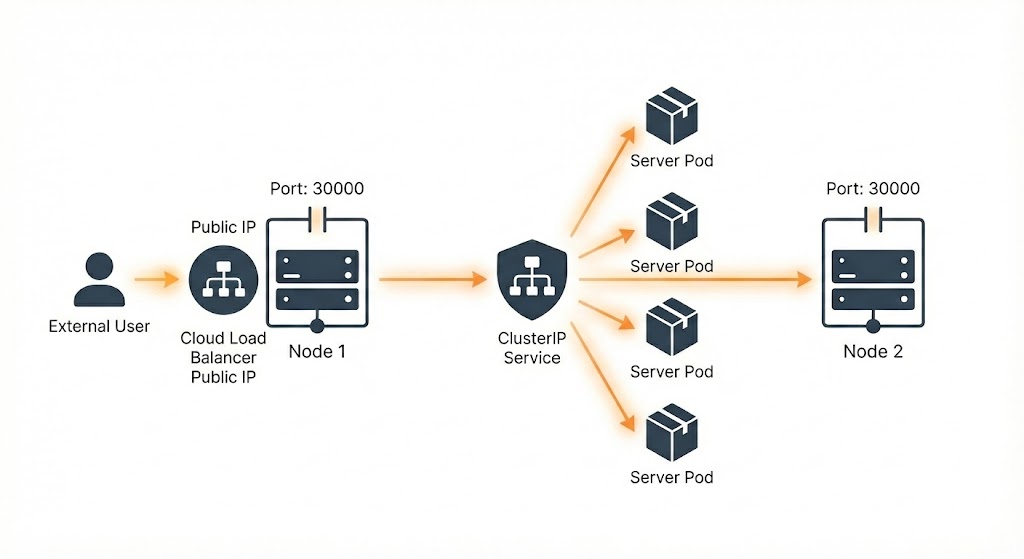
앞서 살펴본 NodePort는 외부 접근을 가능하게 하지만, 실제 상용(Production) 서비스에 그대로 사용하기에는 한계가 명확합니다.
1) NodePort의 한계: “주소가 너무 많다”
여러 노드에 걸쳐 파드가 배포된 상황을 가정해 봅시다. NodePort를 사용하면 사용자는 아래와 같이 수많은 엔드포인트 중 하나를 선택해서 접속해야 합니다.
http://192.168.56.70:30035http://192.168.56.71:30035...http://192.168.56.73:31002
하지만 실제 사용자는 단 하나의 깔끔한 URL(예: www.myapp.com)로 접속하기를 원합니다. 사용자가 노드의 IP나 포트 번호를 일일이 알 필요는 없어야 합니다.
2) 수동 구성의 어려움 (Self-Hosted LB)
이를 해결하기 위해 별도의 서버(Virtual Machine)에 Nginx나 HAProxy 같은 로드밸런서를 직접 설치하고, 트래픽을 각 노드로 라우팅하도록 구성할 수도 있습니다. 하지만 이 방식은 관리 포인트가 늘어납니다. 노드가 추가되거나 IP가 바뀔 때마다 로드밸런서 설정을 매번 수정해야 하며, 로드밸런서 자체의 고가용성(HA)까지 신경 써야 하기 때문입니다.
3) 클라우드 네이티브 해결책: LoadBalancer 타입
AWS, GCP, Azure와 같은 클라우드 환경(또는 MSP)에서 쿠버네티스를 사용한다면, LoadBalancer 타입이 가장 확실한 해답입니다.
yamlapiVersion: v1
kind: Service
metadata:
name: myapp-service
spec:
type: LoadBalancer # 클라우드 제공자의 LB 사용
ports:
- port: 80
targetPort: 80
selector:
app: myapp
이 타입으로 서비스를 생성하면 다음과 같은 일들이 자동으로 발생합니다.
- 자동 프로비저닝: 쿠버네티스가 클라우드 제공자에게 요청을 보내 실제 로드밸런서 장비(또는 리소스)를 자동으로 생성합니다.
- 단일 진입점 제공: 클라우드 제공자는 외부에서 접속 가능한 고정 공인 IP(Public IP)를 할당해 줍니다.
- 자동 라우팅 관리: 로드밸런서는 클러스터 내의 건강한(Healthy) 노드들을 자동으로 감지하고 트래픽을 분산시킵니다. (백그라운드에서는 NodePort가 자동으로 생성되어 연결됩니다.)
이 타입의 사용으로 개발자는 복잡한 라우팅 설정이나 IP 관리를 신경 쓸 필요 없이, 클라우드가 제공하는 고성능 로드밸런서를 통해 서비스를 안전하게 외부에 노출할 수 있습니다.
🧑🏼💻 클라우드(EKS, GKE)가 아닌 온프레미스 환경에서는 LoadBalancer를 못 쓰나요?
기본적으로는 사용할 수 없습니다.
클라우드 환경이 아니라면,type: LoadBalancer로 서비스를 생성해도 연결해 줄 외부 로드밸런서가 없기 때문에External-IP는 영원히<pending>상태로 남게 됩니다.
하지만 MetalLB와 같은 베어메탈용 로드밸런서 구현체를 추가로 설치하면 사용 가능합니다. MetalLB는 미리 정의된 IP 풀(Pool)에서 IP를 할당하고, 표준 라우팅 프로토콜(ARP, BGP)을 사용하여 클라우드 로드밸런서와 유사한 환경을 온프레미스에서도 구축할 수 있게 도와줍니다.
👨🏻💻 코드 팁
expose , create 명령어로 yaml 생성
| 명령어 | 장점 (👍) | 단점 (👎) |
|---|---|---|
kubectl expose | Pod의 라벨을 자동으로 가져옴 (연결 확실함) | NodePort 번호(예: 30080)를 직접 지정 못 함 |
kubectl create | NodePort 번호 지정 가능 | 라벨을 app=이름으로 제멋대로 가정함 (연결 끊길 위험 큼) |
추천 흐름
1. expose로 뼈대 만들기
파드의 라벨을 정확히 가져오기 위해 kubectl expose 명령어를 사용합니다.
예시1) NodePort
bashkubectl expose pod nginx --type=NodePort --port=80 --name=nginx-service --dry-run=client -o yaml > svc.yaml
# kubectl create service nodeport nginx --tcp=80:80 --node-port=30080 --dry-run=client -o yaml
예시2) ClusterIP
bashkubectl expose pod redis --port=6379 --name redis-service --dry-run=client -o yaml
2. 파일 수정하기 (vi svc.yaml)
NodePort의 경우 생성된 파일 열어서 nodePort: 30080만 한 줄 추가합니다.
ClusterIP는 상관없습니다.
3. 적용하기
kubectl apply -f svc.yaml
4. 참고
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
https://kubernetes.io/docs/reference/kubectl/conventions
create service는 라벨이 틀릴 위험이 있으니,expose명령어로 YAML을 뽑아낸 뒤 필요한 부분(NodePort 번호 등)만 수정해서 쓰는 것이 좋습니다.
👨🏻💻 실습
How many Services exist on the system?
bashkubectl get service kubectl get svc
bashcontrolplane ~ ➜ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 5m16s
- That is a default service created by Kubernetes at launch.
What is the type of the default kubernetes service?
bashcontrolplane ~ ➜ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 5m16s
- ClusterIP
What is the targetPort configured on the kubernetes service?
bashkubectl describe svc kubernetes
bashcontrolplane ~ ➜ kubectl describe svc kubernetes Name: kubernetes Namespace: default Labels: component=apiserver provider=kubernetes Annotations: <none> Selector: <none> Type: ClusterIP IP Family Policy: SingleStack IP Families: IPv4 IP: 10.43.0.1 IPs: 10.43.0.1 Port: https 443/TCP TargetPort: 6443/TCP Endpoints: 10.244.213.53:6443 Session Affinity: None Internal Traffic Policy: Cluster Events: <none>
How many labels are configured on the kubernetes service?
위에서 보면
component=apiserver, provider=kubernetes ⇒ 2개
How many Endpoints are attached on the kubernetes service?
bashcontrolplane ~ ➜ kubectl describe svc kubernetes ... ... Endpoints: 10.244.1.5:80 <-- 여기가 핵심!
Endpoints: 서비스 리소스 상세 정보를 보면 Endpoints라는 항목이 있습니다. 이곳에는 서비스가 트래픽을 보낼 실제 파드들의 IP와 Port 정보가 나열됩니다.
- 정상적인 경우:
Selector조건에 맞는 파드가 3개라면, Endpoints에도 3개의 IP 주소가 보여야 합니다. - 비정상적인 경우: 만약 이곳이 비어있다면(
<none>), 서비스는 생성되었지만 트래픽을 보낼 파드를 하나도 찾지 못했다는 뜻입니다.
위 예시에서는 1개의 Endpoint(10.244.1.5:80)가 확인됩니다. 이는 현재 서비스가 1개의 파드와 정상적으로 연결되었음을 의미합니다.
Create a new service to access the web application using the service-definition-1.yaml file.
Name:webapp-serviceType:NodePorttargetPort:8080port:8080nodePort:30080selector:simple-webapp
https://kubernetes.io/ko/docs/concepts/services-networking/service/ ⇒ 여기서 yaml 복사해도 좋음
yamlapiVersion: v1
kind: Service
metadata:
name: webapp-service
namespace: default
spec:
type: NodePort
ports:
- nodePort: 30080
port: 8080
targetPort: 8080
selector:
name: simple-webapp